Recently we kicked off the development of a new feature. Large scale reconstruction. Our vision is to enable users to reconstruct large areas with low cost sensors on mobile devices. This post shows the initial developments in boundless reconstruction.
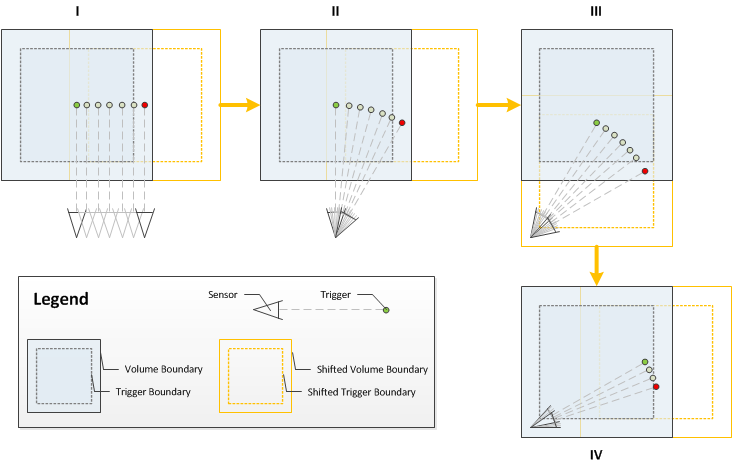
Many approaches could be applied to enable this feature. After an evaluation we finally decided for a solution which integrates nicely into ReconstructMe. That is, we translate the volume along canonical directions and keep track of the camera position in world space. Once we determine how to shift, we need to figure out when to shift.
We decided to go with the concept of what we call trigger boundaries that are relative to the volume. When a specific point crosses this boundary, the volume will be shifted. The first approach was to position the camera at the center of the volume. Once the camera position crossed the boundary, the volume was shifted. We found that this concept did not perform ideally, since the data behind the camera is allocated but most likely not captured and thus wasteful. After evaluating different options, we settled with the idea to specify the trigger point as the center of the view frustum in camera space. Again, when the trigger point crosses the trigger boundary the volume is shifted into the dimension of the cross occurence.
In testing we faced the issue that ReconstructMe requires decent computation hardware and its rather tedious to move around with a full blown desktop PC or gamer notebook. Luckily, a old feature called file sensor helped us to speed up testing and data acquisition. Recording a stream of a depth camera does not require a lot of hardware resources and can be performed on Windows 8 tablets (Asus Transformer T100 in this case).
The streams were used to test the approach and to extract a colorized point cloud of the global scanned area. The tests showed a drift of the camera which was expected. Nonetheless, ReconstructMe is able to reconstruct larger areas without any problems if enough geometric information is available.








Based on our initial experiences, we plan to invest into more research in robust camera tracking algorithms, loop closure detection and mobility. Additionally we will need to settle with a workflow for the user interface and at the SDK level.